正则表达式(Regular Expression)是一种字符串匹配的模式(规则)
使用场景:
- 例如验证表单:手机号表单要求用户只能输入11位的数字 (匹配)
- 过滤掉页面内容中的一些敏感词(替换),或从字符串中获取我们想要的特定部分(提取)等
语法
- 定义正则表达式语法
- 判断是否有符合规则的字符串
test()方法 用来查看正则表达式与指定的字符串是否匹配- 如果正则表达式与指定的字符串匹配 ,返回
true,否则false
1
2
3
4
5
6
7
8
9
10
11
| <body>
<script>
const str = 'web前端开发'
const reg = /web/
console.log(reg.test(str))
console.log(reg.test('java开发'))
</script>
</body>
|
- 检索(查找)符合规则的字符串
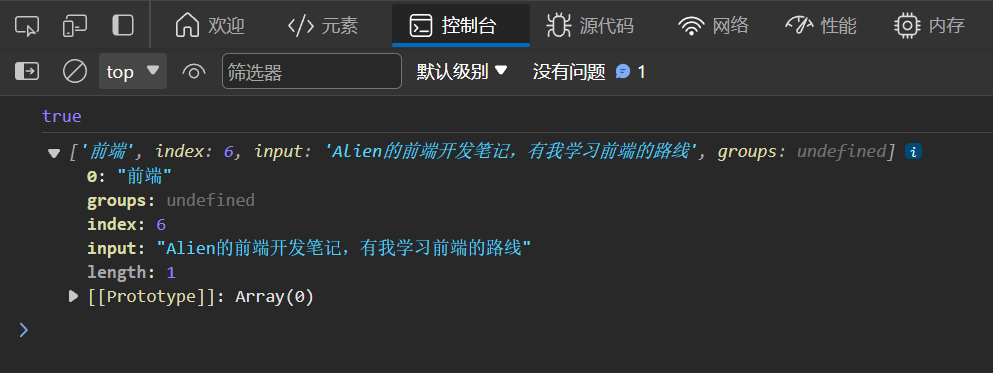
exec()方法,在一个指定字符串中执行一个搜索匹配- 如果匹配成功,exec()方法返回一个数组,否则返回null
1
2
3
4
| const str = 'Alien的前端开发笔记,有我学习前端的路线'
const regObj = /前端/
console.log(regObj.test(str))
console.log(regObj.exec(str))
|
元字符
- 普通字符:
- 大多数的字符仅能够描述它们本身,这些字符称作普通字符,例如所有的字母和数字。
- 普通字符只能够匹配字符串中与它们相同的字符。
- 比如,规定用户只能输入英文26个英文字母,普通字符的话 /abcdefghijklmnopqrstuvwxyz/
- 元字符(特殊字符)
- 一些具有特殊含义的字符,可以极大提高了灵活性和强大的匹配功能。
- 比如,规定用户只能输入英文26个英文字母,换成元字符写法: [a-z]
- 参考文档
边界符
正则表达式中的边界符(位置符)用来提示字符所处的位置,主要有两个字符
| 边界符 |
说明 |
| ^ |
表示匹配行首的文本(以谁开始) |
| $ |
表示匹配行尾的文本(以谁结束) |
如果 ^ 和 $ 在一起,表示必须是精确匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| <body>
<script>
const reg = /^web/
console.log(reg.test('web前端'))
console.log(reg.test('前端web'))
console.log(reg.test('前端web学习'))
console.log(reg.test('we'))
const reg1 = /web$/
console.log(reg1.test('web前端'))
console.log(reg1.test('前端web'))
console.log(reg1.test('前端web学习'))
console.log(reg1.test('we'))
const reg2 = /^web$/
console.log(reg2.test('web前端'))
console.log(reg2.test('前端web'))
console.log(reg2.test('前端web学习'))
console.log(reg2.test('we'))
console.log(reg2.test('web'))
console.log(reg2.test('webweb'))
</script>
</body>
|
量词
量词用来设定某个模式出现的次数
| 量词 |
说明 |
| * |
重复零次或更多次 |
| + |
重复一次或更多次 |
| ? |
重复零次或一次 |
| {n} |
重复n次 |
| {n,} |
重复n次或更多次 |
| {n,m} |
重复n到m次 |
注意: 逗号左右两侧千万不要出现空格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| <script>
const reg1 = /^w*$/
console.log(reg1.test(''))
console.log(reg1.test('w'))
console.log(reg1.test('ww'))
const reg2 = /^w+$/
console.log(reg2.test(''))
console.log(reg2.test('w'))
console.log(reg2.test('ww'))
const reg3 = /^w?$/
console.log(reg3.test(''))
console.log(reg3.test('w'))
console.log(reg3.test('ww'))
const reg4 = /^w{3}$/
console.log(reg4.test(''))
console.log(reg4.test('w'))
console.log(reg4.test('ww'))
console.log(reg4.test('www'))
console.log(reg4.test('wwww'))
const reg5 = /^w{2,}$/
console.log(reg5.test(''))
console.log(reg5.test('w'))
console.log(reg5.test('ww'))
console.log(reg5.test('www'))
const reg6 = /^w{2,4}$/
console.log(reg6.test('w'))
console.log(reg6.test('ww'))
console.log(reg6.test('www'))
console.log(reg6.test('wwww'))
console.log(reg6.test('wwwww'))
</script>
|
范围
表示字符的范围,定义的规则限定在某个范围,比如只能是英文字母,或者数字等等,用表示范围
| 字符 |
说明 |
| [abc] |
匹配包含的单个字符,也就是a||b||c,多选一 |
| [a-z] |
连字符,用来指定字符范围,[a-z]表示a到z的26个字母 |
| [^abc] |
取反符,表示匹配除了26个小写字母以外的字符 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| <body>
<script>
const reg1 = /^[abc]$/
console.log(reg1.test('a'))
console.log(reg1.test('b'))
console.log(reg1.test('c'))
console.log(reg1.test('d'))
console.log(reg1.test('ab'))
const reg2 = /^[a-z]$/
console.log(reg2.test('a'))
console.log(reg2.test('p'))
console.log(reg2.test('0'))
console.log(reg2.test('A'))
const reg3 = /^[a-zA-Z0-9]$/
console.log(reg3.test('B'))
console.log(reg3.test('b'))
console.log(reg3.test(9))
console.log(reg3.test(','))
const reg4 = /^[a-zA-Z0-9_]{6,16}$/
console.log(reg4.test('abcd1'))
console.log(reg4.test('abcd12'))
console.log(reg4.test('ABcd12'))
console.log(reg4.test('ABcd12_'))
const reg5 = /^[^a-z]$/
console.log(reg5.test('a'))
console.log(reg5.test('A'))
console.log(reg5.test(8))
</script>
</body>
|
字符类
常见模式的简写方式
| 预定类 |
说明 |
| \d |
匹配0-9之间的任意数字,相当于[0-9] |
| \D |
匹配所以0-9以外的字符,相当于[^0-9] |
| \w |
匹配任意的字母、数字和下划线,相当于[A-Za-z0-9_] |
| \W |
除所以字母、数字和下划线以外的字符,相当于[^A-Za-z0-9_] |
| \s |
匹配空格(包括换行符、制表符、空格符等),相当于[\t\r\n\v\f] |
| \S |
匹配非空格的字符,相当于[^\t\r\n\v\f] |
1
| 日期格式:^\d{4}-\d{1,2}-\d{1,2}
|
替换和修饰符
replace() 替换方法,可以完成字符的替换
1
2
3
4
5
6
7
8
| <body>
<script>
const str = '认真学习前端,相信一定能学好前端'
const strEnd = str.replace(/前端/, 'web')
</script>
</body>
|
修饰符约束正则执行的某些细节行为,如是否区分大小写、是否支持多行匹配等
- i 是单词 ignore 的缩写,正则匹配时字母不区分大小写
- g 是单词 global 的缩写,匹配所有满足正则表达式的结果
1
2
3
4
5
6
7
8
| <body>
<script>
const str = '认真学习前端,相信一定能学好前端'
const strEnd = str.replace(/前端/g, 'web')
console.log(strEnd)
</script>
</body>
|
